Python Multithreading Tutorial: Everything You Need to Know
 Parallelism is important to contemporary programming. Indeed, the reasons for executing many pieces of code concurrently are limitless. Scalability, efficacy — the list goes on. Regardless of the cause, multithreading is a straightforward method of achieving parallelism in Python. Thus, this Python threading tutorial will walk you through the steps necessary to develop multithreading. This also applies to the use of Queues for inter-thread communication!
Parallelism is important to contemporary programming. Indeed, the reasons for executing many pieces of code concurrently are limitless. Scalability, efficacy — the list goes on. Regardless of the cause, multithreading is a straightforward method of achieving parallelism in Python. Thus, this Python threading tutorial will walk you through the steps necessary to develop multithreading. This also applies to the use of Queues for inter-thread communication!

Python Threading Tutorial Theory about Python Multithreading Tutorial: Everything You Need to Know
Before we can dive into parallelism, we should cover some theory. In fact, this section will explain why you need parallelism. After that, it will cover the basic jargon you need to know.Why do we need parallelism?
Parallelism is a straightforward notion. This signifies that your software executes many of its components concurrently. They might be distinct components or even several instances of the same component. Each, however, operates independently of the other. Parallelism refers to the simultaneous execution of numerous components of your program. Of course, this adds a layer of complication, so why would we do so? Couldn't we simply use a single monolithic program that performs all operations sequentially? We could, but the performance would be significantly reduced. Indeed, parallelism provides two primary advantages. Horizontal scalability: work may be distributed over several cores on a single machine or even across multiple systems. This implies that you may get more computing power and have more simply by adding machines to the cluster. This is the polar opposite of vertical scalability, in which the hardware of the same machine must be upgraded. Consider the following scenario: certain sections of your script need a delay, but others do not. You may have just the bits that really need waiting do so, while the others proceed.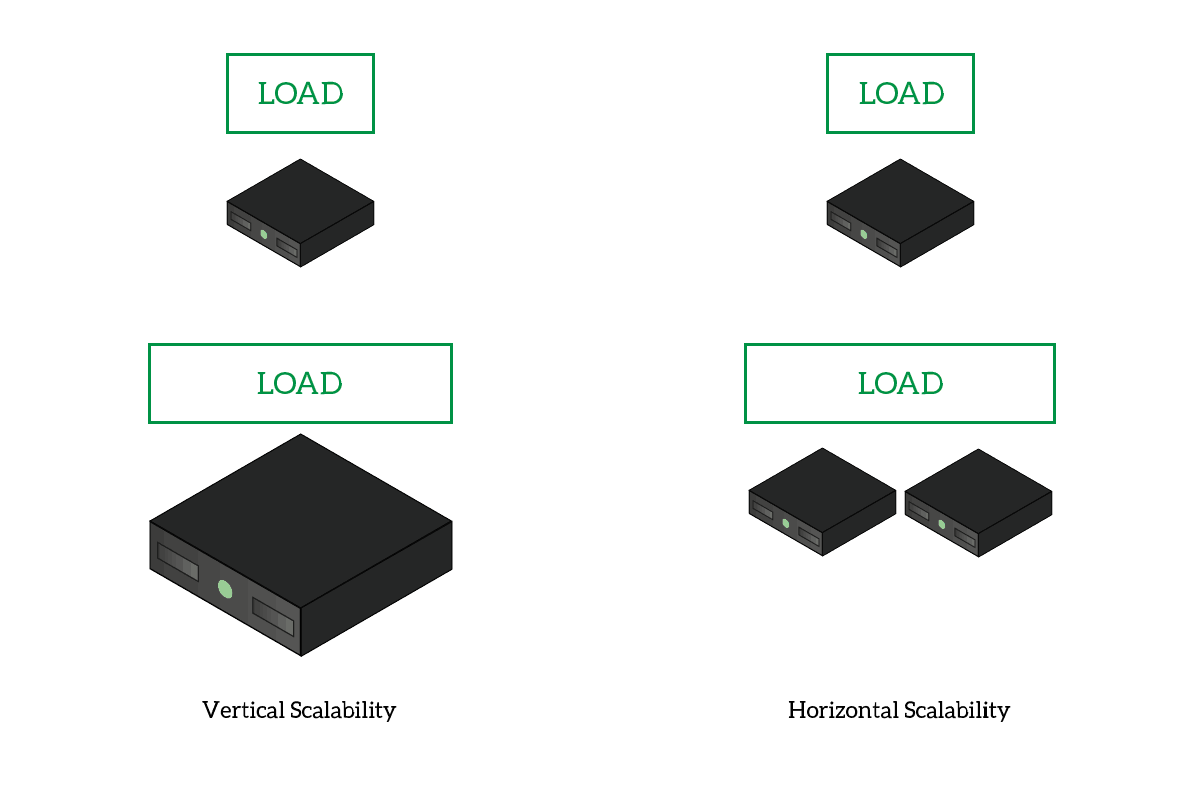
Multithreading and Multiprocessing
Parallelism may be achieved in two ways: multithreading and multiprocessing. Both may do the same thing in two distinct ways. A process is a computer program that is currently operating. The operating system will allot some memory to the process and some meta-information necessary to deal with it. This is truly a whole program in operation. Rather than that, a thread is a simplified form of a process. It is not a running program, but a portion of one. It is a thread that is associated with a process and shares memory with other threads in the same process. Additionally, the operating system is relieved of the responsibility of allocating the thread's meta-information. A process is a running program. A thread is only one component of a process. For basic tasks, like as executing a function, using several threads is the optimal solution. Indeed, this Python threading lesson will demonstrate how to use threads to create parallelism. The same techniques might be used to multiprocessing as well.Multithreading Jargon
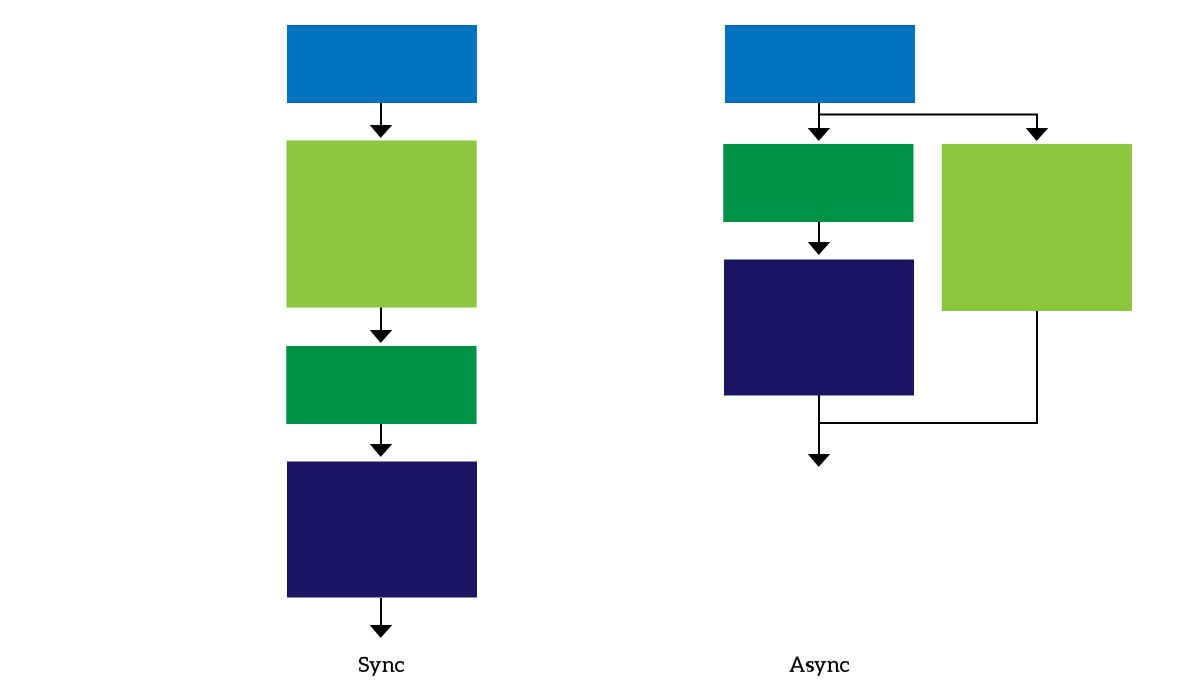
This section of this python threading tutorial is important. If you get the jargon right, understanding the whole article will be a lot easier. Despite being a complex topic, the jargon of python threading is not complex at all.Sync and Async
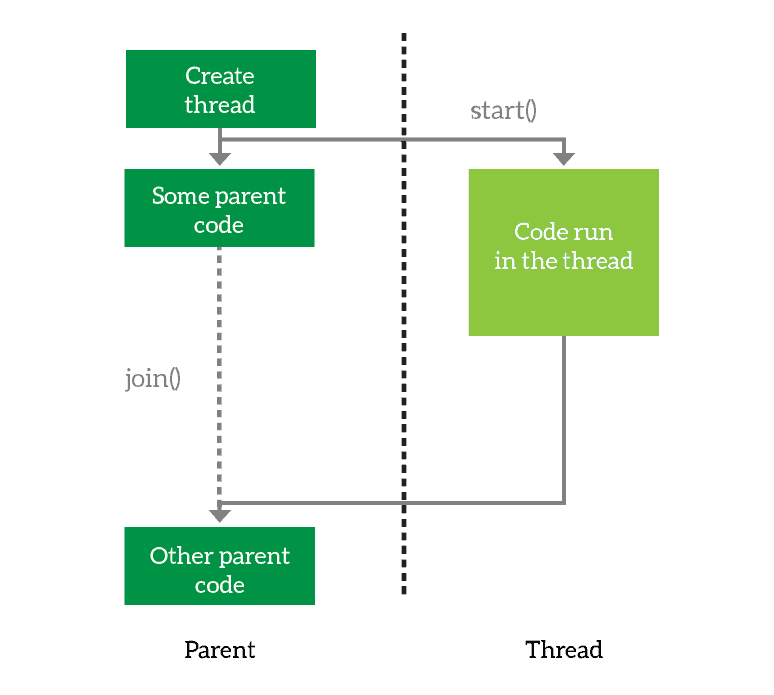
Running threads
Read More: Cisco ISDN Configuration and Troubleshooting
Hands-On on this Python Threading Tutorial
Python threading library
Python has several ways to implement multithreading. The modern way to do it is using thethreading library, which contains the Thread class. As we will see, working with this library is extremely intuitive. We also want to use the time library to experiment threads, but this is not strictly needed in production. Thus, at the very beginning of your script, add the following lines.
import threading
import time
Define a test function to run in threads
First thing, we need to define a function we want to run in a thread. Our function will do almost nothing, but we will use thesleep() function to emulate a huge workload. The sleep() function makes your program (or thread) stop and wait for a given amount of seconds.
When you have a function that you want to run in a thread, it is best practice to use a thread identifier as the first parameter. This way, you know what thread you are running from inside the function as well. However, you also need to pass this value when creating the thread, but we will get to that. For now, just create this function.
def do_something(id, message=''):
time.sleep(4)
print("Thread #" + str(id) + " finished with message: " + message)
Running it synchronously “the standard way”
At this point, we can create a global list of messages that we want to print. Here is an example.messages = [
'This is my first multithreading script',
'Here is a message',
'It works!',
'Python threading tutorial'
]
do_something() function with all the messages synchronously we would roughly need 16 seconds (4 seconds per message). In fact, we can do a simple test using the time.time() function. This returns the epoch time in seconds, and we can use it twice to see how much time elapsed from the beginning to the end of the script.
start = time.time()
for i, msg in enumerate(messages):
do_something(i, msg)
print("It took " + str(time.time()-start) + " seconds")
C:\Users\aless\Desktop>python threads.py
Thread #0 finished with message: This is my first multithreading script
Thread #1 finished with message: Here is a message
Thread #2 finished with message: It works!
Thread #3 finished with message: Python threading tutorial
It took 16.003358125686646 seconds
C:\Users\aless\Desktop>Running it with threads
Now we can dive in the real python threading tutorial. We can rewrite this part of the script to work with threads, and distribute the load among them. Here we need to work with three different functions.Creating the thread
To create a thread, you need to instantiate athreading.Thread object. The constructor wants to know a target function: the function that you want to run within the thread. It also want to know a list of parameters you want to pass to the function, if you need it. You provide the function name as target, and the parameters as a tuple for the args parameter. Below, a sample code to create a thread.
thread = threading.Thrad(target=function_name, args=(arg1, arg2, arg3))
Starting and joining the thread
Once you have a thread object, you can decide to start it with thestart() function, and to join it with the join() function, as simple as that. The code is pretty straight forward, as you can see below.
thread.start()
thread.join()
join(), you need to call start() first. However, you don’t need to call the two one after the other. In fact, you might want to perform some code after starting the thread, and before joining it. Even more, you may not join a thread all.
The whole script
Combining the commands above, we can create a way more efficient snippet that leverages threads. Here it is.start = time.time()
threads = []
for i, msg in enumerate(messages):
threads.append(threading.Thread(target=do_something, args=(i, msg,)))
threads[i].start()
for thread in threads:
thread.join()
print("It took " + str(time.time()-start) + " seconds")
C:\Users\aless\Desktop>python threads.py
Thread #1 finished with message: Here is a message
Thread #0 finished with message: This is my first multithreading script
Thread #3 finished with message: Python threading tutorial
Thread #2 finished with message: It works!
It took 4.001831293106079 seconds
C:\Users\aless\Desktop>
Read More: Cisco ISDN Configuration and Troubleshooting
Inter-thread communication with Queues
Running threads is great. You can genuinely apply parallelism, and make your script more efficient. However, thus far we saw simply how to give arguments to a thread. A stub function that just runs code but that does not return anything has limited applicability, and we know it. We need to have our threads return something, however this comes with some complications.The challenges of communication between threads
Why can’t a thread return anything at conclusion, much as a function does? Many individuals raise this question when first exploring parallel programming. The reason for such is the asynchronous nature of threads. When does the return should happen? What should the parent script do till it receives a return? If you only wait for the complete thread to be run, you may use a synchronous function as well. Instead, threads are meant to not be alternatives to functions. They serve a totally new function, and they do not precisely return anything. Instead, they may connect with the script that formed the thread, or with other siblings threads both for input and output. Here we have another challenge: concurrency. What happens if two threads attempt to write the value of a variable at the same time? You risk executing the same code again, generating unexpected behavior. A popular example is a bank balance script. In order to approve a withdrawal, the script first checks whether there are enough money in the account. What if the balance changes between the check and the effective withdrawal? You withdraw the money you don’t have. Python supports various libraries to prevent this sort of difficulty, and today we are going to work with the most versatile:queue.
Introducing the Queue
The queue. Queue object is a specific item that we may utilize to manage concurrency. It can operate as a shared variable across threads since it can handle concurrency concerns appropriately. You may think of a queue as a list, where you can place things and subsequently get them. In an usual configuration, you will have some portion of the code loading the queue, and some other reading it and processing its contents. Think of it as an upgraded list. The function, or component of the code, that inserts an item into the queue is the producer. Instead, the function processing (and consequently deleting) items from the queue is the consumer. In order to use Queue, we need to import its library. Thus, we can add the following line of code at the beginning of our script.import queue
The simplest consumer
We first need to rewrite ourdo_something() function. Now, it is not just a function that runs once in a thread. It is a whole consumer, a function that tries to process an entire queue. Then, we can run this as a separate thread. And, to speed things up, we can instantiate more do_something threads to process the queue faster. Here is the code.
def do_something(id, message_queue):
while not message_queue.empty():
message = message_queue.get()
time.sleep(4)
print("#" + str(id) + ": " + message)
print("\t Thread #" + str(id) + " finished.")
Queue. Then, as long as the queue is not empty, it will fetch a message (message_queue.get()) and print it. As soon as the queue is empty, it will tell you that the thread finished and exit. Remember, on a queue, the get() method returns the oldest object that was inserted in the queue, and removes from it. So, the first time it will return the object added first, the second time the object added second and so on.
It is very important, at least for now, that you put the get() right after the check for empty(). If you sleep before that, you risk that a thread tries to fetch from a queue that is empty (because another thread fetched after our thread checked). This will make this more unlikely, but won’t solve the problem. To solve the problem, read on.
To see how this works, we should increase the size of our messages object. We can do that simply by multiplying it by, say, 10.
messages = [
'This is my first multithreading script',
'Here is a message',
'It works!',
'Python threading tutorial'
] * 10
Populating the Queue from the parent
Before going deeper into the concept of producer, we should move with small steps. Thus, the next thing to do in this Python threading tutorial is populating the queue from the parent script. In other words, we have a queue that already exists, and we start several threads to process it. The script is now a little bit more complex, but nothing we can’t tackle down.start = time.time()
q = queue.Queue()
threads = []
num_of_threads = 2
for msg in messages:
q.put(msg)
for thid in range(num_of_threads):
threads.append(threading.Thread(target=do_something, args=(thid, q,)))
threads[thid].start()
for thread in threads:
thread.join()
print("It took " + str(time.time()-start) + " seconds")
q, and then we populate it with the put() function. This is like append() on lists, it adds an item at the end. After that, we have our major change. We decide how many threads instantiate according to the num_of_threads variable. Each thread receives its unique identifier and the same q. We launch them and then join them. This script will use only 2 threads to process the queue, and these threads will terminate as soon as the queue is empty. With two threads, the script should complete in about 80 seconds as in the formula below.
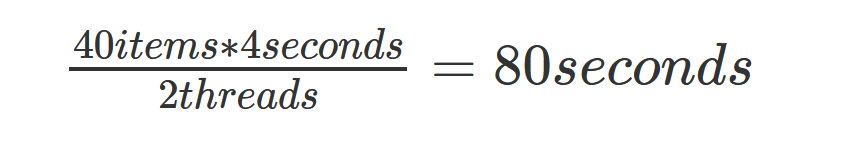
C:\Users\aless\Desktop>python threads.py
#1: Here is a message
#0: This is my first multithreading script
#0: Python threading tutorial
#1: It works!
< omitted output >
#1: This is my first multithreading script
#0: Here is a message
#1: It works!
Thread #1 finished.
#0: Python threading tutorial
Thread #0 finished.
It took 80.01445055007935 secondsScaling it up
With this approach of consumers, you can easily run more threads to make your script runs faster. All you need to do is increase the value of the num_of_threads variable. By setting it to 20, the output is the one below.C:\Users\aless\Desktop>python threads.py
#0: This is my first multithreading script
#3: Python threading tutorial
#1: Here is a message
#2: It works!
#7: Python threading tutorial
#5: Here is a message
#6: It works!
#4: This is my first multithreading script
#11: Python threading tutorial
#8: This is my first multithreading script
#9: Here is a message
#10: It works!
#12: This is my first multithreading script
#14: It works!
#13: Here is a message
#15: Python threading tutorial
#19: Python threading tutorial
#18: It works!
#17: Here is a message
#16: This is my first multithreading script
#0: This is my first multithreading script
Thread #0 finished.
#6: It works!
#7: This is my first multithreading script
#5: Here is a message
Thread #5 finished.
#3: Here is a message
Thread #3 finished.
#2: Python threading tutorial
#1: It works!
Thread #7 finished.
#4: Python threading tutorial
#9: It works!
Thread #6 finished.
#11: This is my first multithreading script
Thread #4 finished.
#15: Python threading tutorial
#10: Python threading tutorial
#16: Python threading tutorial
#14: Here is a message
#19: This is my first multithreading script
Thread #1 finished.
Thread #11 finished.
#12: This is my first multithreading script
Thread #2 finished.
#17: It works!
#13: It works!
Thread #9 finished.
#8: Here is a message
Thread #15 finished.
Thread #10 finished.
Thread #17 finished.
Thread #13 finished.
#18: Here is a message
Thread #12 finished.
Thread #14 finished.
Thread #8 finished.
Thread #16 finished.
Thread #18 finished.
Thread #19 finished.
It took 8.015052080154419 secondsA sentinel watching our threads
When we introduced theempty() method on a queue, we explained that we need to get data from the queue as soon as we verify that it is not empty. If we don’t do that, some other thread may take our data faster, leaving a thread stuck in waiting. We simply can’t rely on being the fastest thread out there. We can’t trust the script to do everything the way we want, every single time. Thus, we need to find another way.
First, checking if the list is empty() has a main problem: in only works if someone filled the queue beforehand. In a real-world scenario, you have a consumer reading from a queue and a producer populating it. Sometimes, the consumer may be faster than the producer and empty the list. This doesn’t mean the producer has finished, and thus the consumer shouldn’t shut-down yet. We can solve this with a sentinel.
A sentinel is a value of our choice that the producer puts in the queue to tell all the consumers it is done producing. Then, you need to implement in the consumer that, as soon as it finds out the sentinel, it stops execution. A common value for a sentinel can be None, if you don’t need to queue objects that may be None.
A sentinel-based consumer
Now, we can re-write our do_something() function again to work with sentinels. Our sentinel here is going to be None.def do_something(id, message_queue):
while True:
message = message_queue.get()
if message is None:
break
time.sleep(4)
print("#" + str(id) + ": " + message)
print("\t Thread #" + str(id) + " finished.")
None item, all the other consumers will be waiting for a None for themselves. However, if the producer doesn’t add any other sentinel, they will be stuck.
We can solve that by adding a None item to the queue each time we add a consumer thread, like below.
start = time.time()
q = queue.Queue()
threads = []
num_of_threads = 20
for msg in messages:
q.put(msg)
for thid in range(num_of_threads):
threads.append(threading.Thread(target=do_something, args=(thid, q,)))
threads[thid].start()
q.put(None)
for thread in threads:
thread.join()
print("It took " + str(time.time()-start) + " seconds")
A consumer-producer script
The whole code
import threading
import time
import queue
import random
import string
def consumer(id, size, in_q):
count = 0
while True:
log_msg = in_q.get()
if log_msg is None:
break
print("0%\t1".format(round(count/size*100,2), log_msg))
count += 1
print("Consumer #0 shutting down".format(id))
def producer(id, in_q, out_q):
while True:
item = in_q.get()
if item is None:
out_q.put(None)
break
out_q.put("#0\tThis string is long 1 characters".format(id, len(item)))
print("Producer #0 shutting down".format(id))
string_q = queue.Queue()
log_q = queue.Queue()
n_of_strings = 200000
for i in range(n_of_strings):
string_q.put(''.join(random.choices(string.ascii_uppercase + string.digits, k=random.randint(0, 150))))
start = time.time()
producers = []
n_of_producers = 2
logger = threading.Thread(target=consumer, args=(0, n_of_strings, log_q,))
logger.start()
for thid in range(n_of_producers):
producers.append(threading.Thread(target=producer, args=(thid, string_q, log_q)))
producers[thid].start()
string_q.put(None)
for thread in producers:
thread.join()
logger.join()
print("It took " + str(time.time()-start) + " seconds")
A quick explanation
In this script, the producer function consumes a queue containing strings and finds the length of each. It then puts a log of each result into another queue, which the consumer then accesses. Since the number of strings is fixed, the consumer can calculate the percentage over the total. We used therandom and string libraries to generate random strings, on-line 31. However, this is not important for our python threading tutorial. Instead, just see that when the producer finishes, it also tells the consumer that it has finished by adding a None item (sentinel) to the output queue.
This script may require some clarification. It performs calculation over calculation and doesn’t do waiting like the scripts we used before. Since the threads of the same process are bound to the same core in the PC, adding more threads won’t increase performance because the limiting factor is the CPU itself, not a waiting the script must do.

Wrapping it up
We presented multithreading in simple terms in the python threading tutorial by using the contemporary libraries threading and queue. While doing so, keep these critical ideas in mind. Threading is used to create a thread.- Thread(). As named parameter target, provide the name of the function to run, and as a tuple, args, the list of arguments to execute.
- You can then work on a thread object's start() method to initiate its execution and have the parent wait for its completion using join ().
- You may make advantage of a queue.
- To facilitate communication between threads, the Queue() object is represented as a list. Put() allows one thread to add items to this queue, while get() allows another thread to read them ().
- Typically, you write a consumer function that runs in a thread and attempts to get items from a queue through an endless loop. You may use the empty() function to determine whether the queue is empty, however this
- may create concurrency concerns. Rather than that, when you are certain you will not add another item to the list, insert an arbitrary value (the sentinel) into the queue. On the other hand, as soon as this value is
- discovered, the endless loop is terminated. To avoid concurrent difficulties, add as many sentinels to a queue as it has consumers.



Comments
Post a Comment